
You’ve probably heard the well-known Hadoop paradox that even on the biggest clusters, most jobs are small, and the monster jobs that Hadoop is designed for are actually the exception.

This is true, but it’s not the whole story. It isn’t easy to find detailed numbers on how clusters are used in the wild, but I recently came across some decent data on a 2011 production analytics cluster at Microsoft. Technology years are like dog years but the processing load it describes remains representative of the general state of things today, and back-of-the-envelope analysis of the data presented in the article yields some interesting insights.
A graph from this article shown below illustrates the job size distribution for one month of processing. The total number of jobs for the month was 174,000, which is equivalent to a job starting every four seconds, round the clock—still a respectable workload today.

The authors make an interesting case for building Hadoop clusters with fewer, more powerful, memory-heavy machines rather than a larger number of commodity nodes. In a nutshell, their claim is that in the years since Hadoop was designed, machines have gotten so powerful, and memory so cheap, that the majority of big data jobs can now run within a single high-end server. They ask if it would not make more sense to spend the hardware budget on servers that can run the numerous smaller jobs locally, i.e., without the overhead of distribution, and reserve distributed processing for the relatively rare jumbo jobs.
Variations of this argument are made frequently, but I’m not writing so much to debunk that idea, as to talk about how misleading the premise that “most Hadoop jobs are small” can be.
Several things are immediately obvious from the graph.
- The X-axis gives job size, and the Y-axis gives the cumulative fraction of jobs that are smaller than x.
- The curve is above zero at 100KB and does not quite hit 1.0 until x is at or near 1PB, so the job size range is roughly 100KB to 1PB, with at least one job at or near each extreme.
- The median job size, i.e., the size for which one half of the jobs are bigger and one-half are smaller (y=0.5) corresponds to a dataset of only 10GB, which is peanuts nowadays, even without Hadoop.
- Almost 80% of jobs are smaller than 1TB.
One glance at this graph and you think, “Wow—maybe we are engineering for the wrong case,” but before getting too convinced, note that the X-axis is represented in log scale. It almost has to be, because were it not, everything up to at least the 1TB mark would have to be squeezed into a single pixel width! Or to put it the other way around, if you scaled the X-axis to the 1GB mark, you’d need a monitor about fifteen miles wide. It is natural to conflate “job count” and “amount of work done” and this is where the log scale can trick you because the largest job processes about 10,000,000,000 times as much data as the smallest job and 100,000 times as much data as the median job.
When you process petabytes, a single terabyte doesn’t sound like much, but even in 2016, 1TB is a lot of data for a single server. Simply reading 1TB in parallel from 20 local data disks at 50MB/sec/disk would take almost 17 minutes even if other processing were negligible. Most 1TB jobs would actually take several times longer because of the time required for such other tasks as decompression, un-marshalling and processing the data, writing to scratch disks for the shuffle-sort, sorting and moving the mapped data from scratch disks to the reducers, reading and processing the reducer input, and ultimately writing the output to HDFS (don’t forget replication.) For many common job types such as ETL and sorting, each of these tasks deals with every row, multiplying the total disk and IPC I/O volume to several times the amount of data read.
An Alternate View
If it takes 17 server/minutes simply to read a terabyte of data for a map-only job with negligible processing and output, it’s a stretch to say that it’s reasonable to run 1TB jobs without distribution, but even so, let’s arbitrarily fix 1TB our upper bound for processing on a single server.
I sketched an inverted view of the same numbers on the original graph. The line is derived by multiplying the change in the number of jobs by the job size. You can’t tell exactly how many of the biggest jobs there are, so I assumed there is only one, which is the weakest assumption.
The data read for 10GB and smaller jobs turns out to be negligible and the cumulative data processed of up to 1TB (the smallest 80% of jobs) is only about 0.01 of the total, which barely clears the y=0 line.
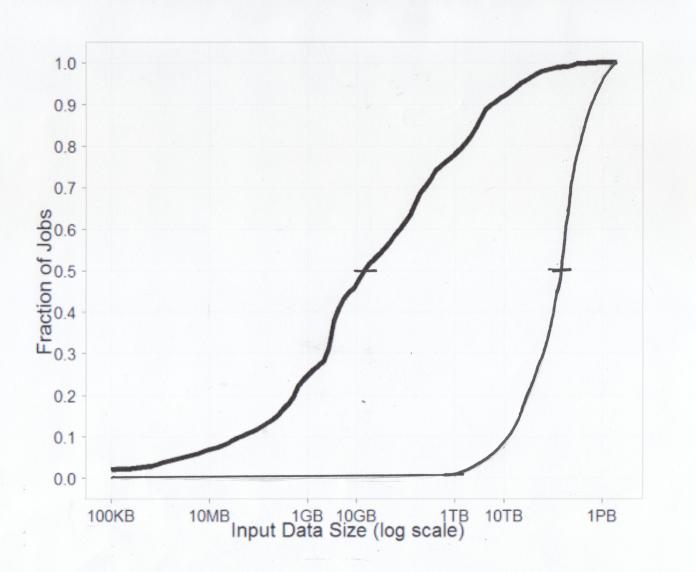
Jobs of up to 10TB in size, which comprises 92% of all jobs, still account for only about 0.08 of the data.
The other 92% of the cluster resources are used by the jobs in the 10TB to 1PB range—big data by any definition.
Consistently with this, “median” now means the job size for which half of the containers are for smaller jobs and half are for larger jobs. Defined this way, the median job size is somewhere in the neighborhood of 100TB, which is four orders of magnitude larger than the median for job count.
Far from supporting the intuition that most of the work is in the form of small jobs, the inverted graph is telling you that at least 99% of the resources are consumed by big jobs, and of that 99%, most is for huge jobs.
Responsiveness and Throughput
Does this mean that there’s nothing useful in knowing the distribution of job sizes, as opposed to resource consumption? Of course not—you just have to be careful what lessons you draw. Cumulative job count and cumulative data processed give very different pictures, but both are important.
The most important thing that the original version of the graph tells us is the critical importance of responsiveness, i.e., how quickly and predictably jobs execute. Big jobs may account for 99% of processing but the user experience is all in the small jobs—responsiveness is huge. Humans don’t really care at a gut-level whether an 8-hour, 1PB job takes an hour or two more or less, but they care a great deal if a Hive query moves from the finger-drumming time scale to the single-second range, which might be a latency difference of only a few seconds. They are particularly annoyed if the same query takes three seconds on one run and 30 seconds on another.
What the inverted version of the graph tells you that the real work is all in the big jobs, where throughput—sheer gigabytes per second—is what matters.
So what does that tell you about big expensive machines? Here’s how it breaks down.
The original motivation for running jobs on a single machine that was cited in the article was increasing efficiency by avoiding the overhead of distribution. However, while a high-end machine can get excellent throughput per-core, the real goal is responsiveness, which is inherently difficult to achieve using a single machine because it requires serializing work that could be done in parallel. Say your killer machine has 32 hardware cores and tons of memory. Even a puny 10GB job still requires 80 map tasks, which means that at least some cores will have to run at least three mappers serially even if the cluster is otherwise idle. Even for tiny jobs, the killer machine would have be three times as powerful to achieve lower latency, even on an idle machine. Moreover, responsiveness is also about minimizing the longest latency. Unless the cluster is idle, the variance in tasks/core will be very high on a single machine. With distributed processing, the work can be dynamically assigned to the least-busy nodes, tightening the distribution of tasks-per-core. By the same token, a 1TB job would require at least 250 mappers running serially on each core. If job is distributed over 100 16-core machines, each core would only have to run five mappers, and workers can be chosen to equalize the load.
For the big jobs, where total throughput, not responsiveness, is the issue, high end machines are a poor bargain. High-end hardware provides more CPU and disk but you get less of each per dollar.
When thinking about Hadoop, you’ll rarely go wrong if you keep in mind that Hadoop jobs are usually I/O bound for non-trivial tasks. Even if, strictly speaking, a particular MR or Tez job is CPU bound, in most cases, a large part of that CPU activity will still be directly in service of I/O: compression and decompression, marshaling and un-marshaling of bulk data, SerDe execution, etc. While high-end machines are best in terms of throughput per core and per disk, those virtues count more for conventional processing.
Conclusion
Hadoop is all about parallelism, not only because it’s critical for big jobs, but because it’s the key to responsiveness for smaller jobs. The virtues of high-end machines don’t count for much in the land of the elephants.
