
This is the first of what I hope will be a series of many posts documenting a pilgrim’s progress from programming to data science.
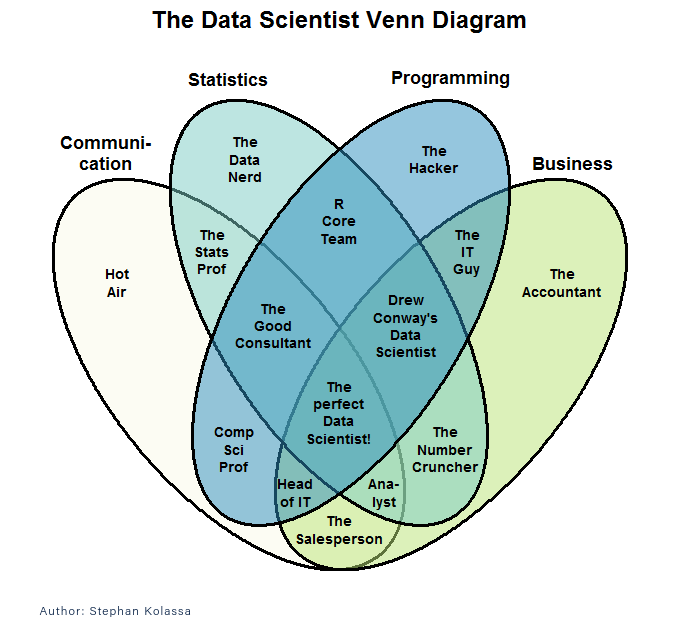
First of all, let’s talk about the name. It is almost a rule that anything called <something>-science isn’t a science and that will hold here. Science is defined as “an intellectual and practical activity encompassing the systematic study of the structure and behavior of the physical and natural world through observation and experiment.”
Nothing about data science fits that definition. It’s in the same boat with disciplines like library science, political science, management science, rocket science, and computer science that use mathematics and/or science to do interesting things but aren’t science themselves.
While the sciences study the world itself, data science studies the techniques for understanding the world through data. Data science is applied to some concrete field, be it science, politics, or advertising, but you wouldn’t say it’s “advertising science.” Of course not–it is its own thing. Trying to fit it in under the heading of science is what philosophers call a category error, like considering the manufacturing of firearms to be branch of wildlife management.
It’s more like engineering but the name “data engineering” is already taken for something else, and it’s not about building or operating things anyway, even in the metaphorical sense that data engineering is. Data science is about how to squeeze meaning and insight from data. It’s about interpretation. So I hereby nominate a new term: data hermeneutics. If the term catches on, I’ll be sure to announce it in a later post.
So if it’s not science, what is it? Data science is a practical activity, an eclectic mix of statistics, applied math, computer science, conventional programming, database programming, algorithms, artificial intelligence and lots and lots of data manipulating grunt-work. It uses all of those fields in service of extracting understanding from raw data. Having only received its name in 2001, the field is younger than a college sophomore. The world hasn’t fully decided exactly what territory data science covers, but with the volume and variety of data in the world increasing exponentially year after year, it’s safe to assume the field will not be shrinking.
A Reboot
I’m not really a data scientist myself. My original background was computer science plus a lot of statistics. In the workplace, I’ve focused on distributed computing, big data, and data engineering, with some work on probabilistic algorithms on the side. I was a director of data engineering for a time. It’s all good stuff for a data scientist but it doesn’t make you one.
For the last year, I’ve been pulling all those things together and remaking myself as a bonafide data scientist. I can see that even though years of programming and statistics are a huge leg up, it’s going to take a while, so I thought I’d start documenting the process. I’m doing this partly so that I can look back at where I’ve been, but also to blaze the trail for others. Many people have been down the path I’m on but it’s easier if someone has gone ahead of you an painted little colored tags on the trees.

Those blazes will be for my particular path but I think they could be generally helpful. For me, even cursory familiarity with a subject gained in advance makes things click and fall into place faster later on. It gives you a mental structure in which to file the avalanche of inbound information.
I have two sons who each did six month data-science boot-camp style programs not long ago, right after college. One of them already had a degree in computer science and the other was about to get a degree in economics but neither had data-specific training in school. The economics guy was barely computer-literate when he started (he is now!) So I’m seeing this for the third time, and it looks like pretty much the same curriculum.
Levels of Preparation
One of the biggest things I’m seeing is that these programs draw an extraordinarily diverse bunch of people. I assume this is because there’s never been a “data science track” churning out uniform entrants into the field. It’s still the wild west. The data science team at the last place I worked had a rocket scientist, a geo-physicist, a statistician, and one person with an actual data science degree. But they all had the same job. In a data science classroom you might find freshly minted statistics and computer science BS’s, grizzled old IT veterans who were moving data across the Internet back when the WWW was a gleam in Sir Tim’s eye, but who are as innocent of math as an English major. There are ex-physicists who dream in eigenvectors and economics majors who have never programmed a word. Data science programs, of necessity, must be geared to some reasonable common denominator of skills.

Programmers and other technical people may find early courses frustrating at first because data science programs seem to assume you don’t know how to so much as spell Python. You can be instructed on what a while-loop is, or how to install Anaconda one too many times, and find yourself near tears, questioning the entire enterprise. Learning a language like Python is barely a speed bump to a programmer; it’s not a semester’s work. It may take some time before your code is truly “Pythonic” in style (as the cool kids say) but a real programmer can write any classroom-level Python program after a weekend of study.
The trouble is, you can’t just sleep though those lectures, because there are key nuggets of the information that you came for sprinkled throughout. You just have to prop you eyelids open with toothpicks, and suck it up for a few weeks while everyone gets to some minimal level set of preparedness.
Goals
The good news is that while initial preparedness levels may be all over the map, programs seem to largely agree on what a new data scientist needs to know. I’ll assume that the reader is either a programmer or will do till a programmer comes along, as the saying goes, that you can use a computer, know what a terminal is, understand what a relational database is and know what SQL is for.
I panicked a little when I first saw the list of of requirements. OMG, I thought–it’s been decades since I took calculus, linear algebra, and statistics! They said they’d have “remedial courses” on some of them and perhaps I could catch up. What a crock—I spent weeks immersing myself in statistics and linear algebra to get ready, but it turned out that I’d have been absolutely fine had I spent that time watching Netflix. No matter how long ago you took those courses, you won’t need more in the first year than Khan Academy and 3Blue1Brown can resurrect. Don’t get me wrong–some of these areas get extremely mathematical when you drill into them but you’re not going to go that deep in a crash course. You can develop that knowledge later as you need it.

I’m not going to try to teach a course in data science, but to lay out what a data-science intro course teaches, minus all the stuff a programmer either knows or can infer. One exception is the tools. Computer science courses often don’t even teach you how to program, let alone how to use basic tools–you are supposed to figure out the trivialities yourself. Let’s not do that here. A lot of the tools are very standard–you just need to know what they are. When they’re optional, I’ll tell you my choices so you have a place to start. You can always swap in your own favorites as you discover them.
We’ll just look at interesting basics without slogging through the rudimentary mechanics. Salman Khan and his troops can get you over the hump if you forget what a Z score is. It’s not a programming or math course. It’s going to be an exercise in cherry picking. Lets have some fun!

“ Trying to fit it in under the heading of science is what philosophers call a category error, like considering the manufacturing of firearms to be branch of wildlife management.” You should be paid for this.
LikeLike