
YARN—the data operating system for Hadoop. Bored yet? They should call it YAWN, right?

Not really—YARN is turning out be the biggest thing to hit big-data since Hadoop itself, despite the fact that it runs down in the plumbing of somewhere, and even some Hadoop users aren’t 100% clear on exactly what it does. In some ways, the technical improvements it enables aren’t even the most important part. YARN is changing the very economics of Hadoop.
Slide decks are generally pretty soporific, and for me, decks with the word “costing” in the title are normally beyond the pale, but I recently came across this deck from last year, by Sumeet Singh, the product manager for Hadoop and Big Data Systems at Yahoo! It is an eye-opener, not because it says anything interesting and new about the tech, but because of the glimpse it gives of what processing big data costs and how radically YARN is changing the picture.
We often hear about tech in terms of algorithms and frameworks, but in a larger sense, it’s always about money, and YARN is having a huge impact on the cost of big-data computing, and with it, what you can afford to do with data.
Uh…What is YARN Again?
YARN is often described as the big-data operating system for modern Hadoop (for Hortonworks Hadoop, that’s 2.x and up) but what does that mean exactly? Hadoop data nodes run on Linux (or sometimes Microsoft) so what’s this “operating system” thing?
The simple answer is that YARN does for cluster resources as a whole what single-machine operating systems such as Linux or Microsoft do for the resources of an individual machine. It puts a simplified abstraction over the cluster resources, and manages allocating their use among many contending users and many kinds of applications.
Hadoop worked without YARN for years, but prior to YARN, it didn’t share resources among multiple users very well. Without YARN, Hadoop is basically a framework for MapReduce batch processing, taking jobs off a single queue and allocating compute resources to them in order as long as free capacity remains. Once all the resources were committed, jobs waited in line, so while Hadoop did well enough with mega-batch jobs, it could be horrendous for smaller interactive Hive jobs in which waiting time and job startup time dominated.
One of YARN’s most obvious benefits is that it allows many users to share the cluster side by side, each with a guaranteed portion of the resources. But this multi-tasking aspect is really just the most visible benefit of something deeper that changes the nature of Hadoop profoundly.
How The Model Changed
Prior to YARN, Hadoop was built around MapReduce as the central compute component. Pig and Hive, the most important higher level services, decomposed their operations into sequences of independent MapReduce jobs that Hadoop ran in containers that were specific to MapReduce. What YARN did was replace the MapReduce containers with generic compute containers that could run any kind of task. Under YARN, MapReduce becomes just one of many applications that can use cluster resources through YARN.
This has benefits that are both diverse and large. For instance, the MapReduce jobs that were the components of a Hive query were independent of each other, and the query as a whole incurred much pointless overhead at each step from all the intermediate HDFS disk writes, replication, and reads for the separate processing phases.
With YARN, a new kind of engine, called Tez became possible. Like MapReduce, Tez deploys the processing as myriad independent containerized tasks, but unlike MapReduce, Tez runs as a strictly client side library, and thus can orchestrate the containers into a single efficient processing graph. Tez can do things like plug the output of one task into the input of the succeeding task via the network, or plug the output of one reducer into another without any intervening map phase. Tez is also aware of users in a way that MapReduce is not, and thus maintains sessions for a user to avoid the overhead of killing off containers that can be used again.
Equally importantly, the same principle of generic resources allows other kinds of compute engines and applications to run on the cluster. Any “YARN Enabled” application, including Spark, HBase and Storm can now share the cluster. This includes both job-oriented applications such as MapReduce, or Pig and Hive over Tez, and long-running services, such as HBase, that provide interactive services that stay up semi-permanently. YARN can even run arbitrary code, such as Bash scripts or Java jobs that can interact with the HDFS file system.
Why Should Anyone But The Techies Care?
As it turns out, the business people should care at least as much as the techies because YARN saves a ton of money. For clusters of modest size there are several benefits:
- The ability to store data from multiple business silos in a single cluster accessible from across the firm.
- Multi-tenancy is practical, allowing fewer clusters with higher utilization.
- Increased processing efficiency from Tez and other optimizations enabled by YARN.
For giant clusters like Yahoo!’s, the improvements in processing efficiency are dramatic. Check out the graph below taken from Singh’s deck. The blue line represents the relentless growth in the amount of raw data storage at Yahoo! The purple line shows number of servers they use to process it. We see the number of servers flattening after 2010, which is what you might expect as the exponentially increasing (Moore’s Law) computing power of newer servers inexorably overtakes the linear increase in data growth, but the curve suddenly turns sharply down with the introduction of YARN.
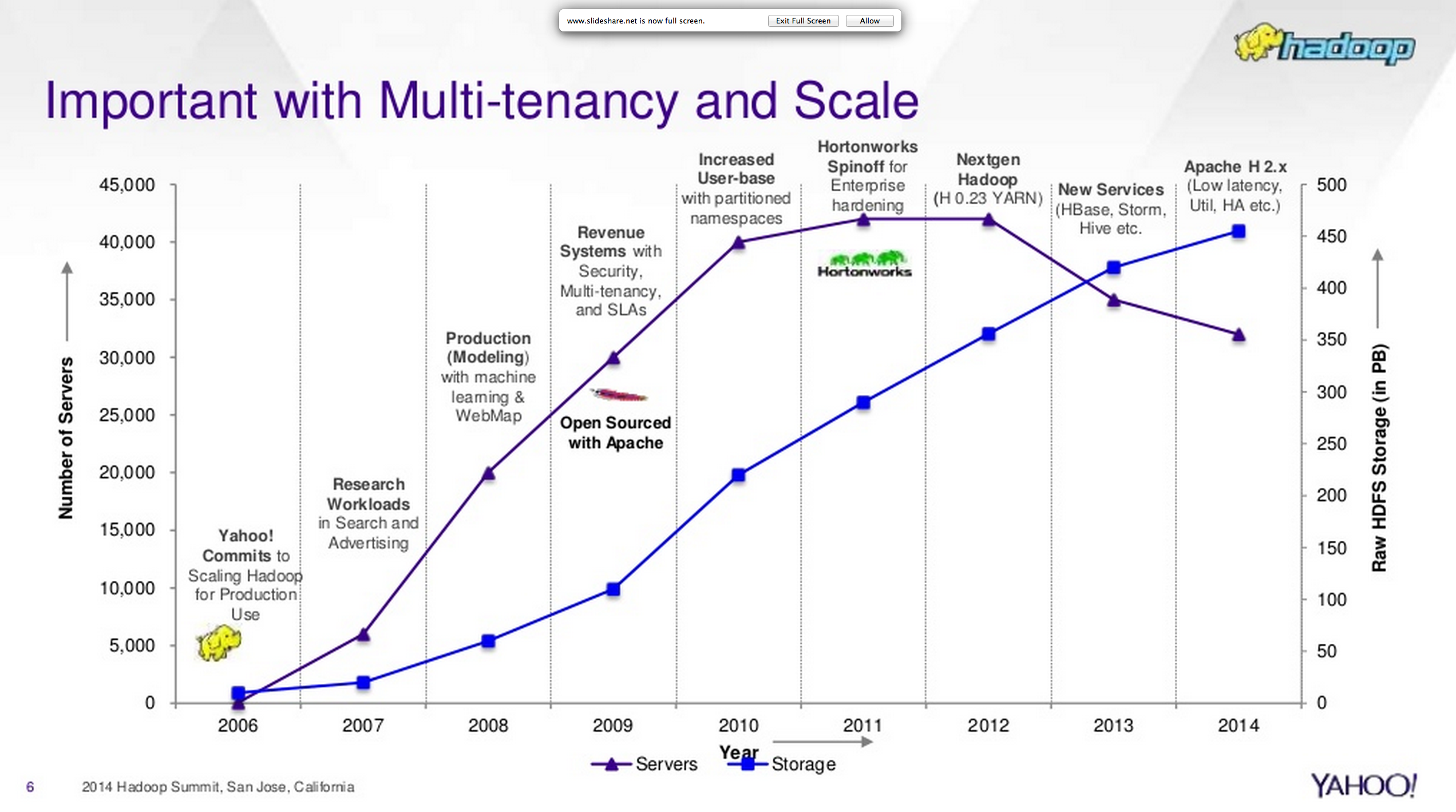
This is striking even in the first graph, but the second graph shows that while the number of servers was dropping by one quarter, the number of jobs increased something like 1.45. In other words, they cut the unit cost of computation in half using YARN. The difference is ten thousand servers, which isn’t small potatoes even for a company the size of Yahoo! It is almost impossible to find out what Yahoo! and other big companies pay for servers, but the low end for commodity servers of the type commonly used by smaller companies is around $7000 to $8000 each. Elsewhere in the deck Singh indicates that the raw cost of a server is about 60% of the total cost of ownership, so if you figure $7000 per server, that would be cost reduction of as much as 117 million dollars. The graphs only cover up to a year ago, but the trends reportedly have continued.

Singh elsewhere cites Pig, Hive, and Oozie as the main processing vehicles at Yahoo!, with Pig and Hive running primarily over Tez. It’s hard to get definitive specifics on where the efficiencies come from, but in large organizations, improvements of this magnitude can only come from either better utilization, increased processing efficiency, or algorithmic improvements.
The sheer diversity of processing at Yahoo! probably rules out algorithmic improvements as a major cause, which leaves utilization and efficiency.
Yahoo!’s usage pattern is extreme. They ran about 33 million Hadoop jobs/month in 2014, or about 11 jobs/second. This inexhaustible supply of jobs means they can run at higher utilization rates than would be possible for almost any other enterprise, so improving utilization rates isn’t the kind of low-hanging fruit that it would be in a more conventional data center.
That leaves greater efficiency as the only real explanation, and YARN increases processing efficiency in several major ways. How exactly these balance at Yahoo! is hard to say, but the gains from YARN generally tend to come from:
The TEZ engine: YARN enables Tez, to which Yahoo! has been moved wholesale. Pig and Hive over Tez run in a fraction of the time they take over MapReduce. Details are job and cluster dependent, but if any Hive job failed to at least double in speed under Tez, it would raise eyebrows, and larger increases are common, particularly for more complex queries.
CapacityScheduler: The multi-queue model of the CapacityScheduler lets more jobs run side by side. With the pre-YARN FIFO scheduling model, each job in turn gets all the resources it can use, up to the limits of availability. Multiple queues are more efficient because limiting the number of containers means jobs get better average container reuse. This is even more true for larger jobs because the proportion of reused containers is commensurately higher. (The YARN FairScheduler also has this property, but the CapacityScheduler is arguably better suited to a multi-tenant or data lake environment. It is allowed, but not supported in HDP.)
Heterogeneous hardware: The YARN innovations relating to heterogeneous hardware are relatively little discussed, and the Yahoo! deck doesn’t say anything about this issue, but other big companies such as eBay are seeing tremendous gains from the YARN and HDFS features that allow multiple data storage types.
Generic Hadoop works best with many disks of modest size. Servers with from 12 to 24 one-TB or two-TB SATA disks are generally used to give a balanced cluster, assuming a typical workload and data sets that are accessed in a fairly uniform pattern. However, if a large part of your data is accessed relatively rarely, or a small part is accessed inordinately often, the ideal balance can be more complex. Cool data, by definition, is accessed less than hot data, and as time goes by, a larger and larger proportion of an organization’s tends to be cool. Less access means that less CPU power per TB necessary to achieve a good hardware balance.
YARN and HDFS together provide at least two ways to take advantage of a heterogeneous mix of hardware.
The HDFS heterogeneous storage mechanism allows disk mount points within generic machines be specified with types SSD, DISK, or ARCHIVE. Various storage policies that indicate the data temperature can then be attached to data files, and HDFS will preferentially store the component blocks in a mix of storage volumes of appropriate types. For instance, a COLD policy would cause all replicas of a file’s blocks to go to ARCHIVE volumes, but a WARM policy would send one block to standard DISK volume and two to ARCHIVE. Hotter and hotter data would have some or all blocks in RAM or SSD volumes for ultra-fast access, with zero or some blocks on slower storage according to policy. The policies also cover what to do when a category of storage is exhausted, and file policies can be changed after they are written; the mover tool will re-jigger data on demand to put the blocks in appropriate storage.
Entire nodes can be assigned an arbitrary type with YARN labels. These labels effectively divide a cluster into sub-clusters of nodes that have the same abstract type. These type designations can be attached to queues, which allows the CapacityScheduler to direct jobs to the desired hardware type. Hardware can be designated as specialized, for instance, for CPU or GPU capacity, and the CapacityScheduler used to offload compute-heavy but data-light work to specialized nodes.
Together, these mechanisms let fewer machines host more data without diminishing the amount of usable CPU power. See this article about eBay’s experience and Apache page on heterogeneous storage for an outline.
It’s Not Over Yet
YARN only became an official Hadoop sub-project in mid 2012, and was not part of a major distribution until the Hortonworks platform’s 2.0 release toward the end of 2013—we can be sure it has not yet had its full impact. The move to multi-tenancy, for which YARN is the most essential component, is only getting started, and ever more kinds of processing are being adapted to run over this flexible platform. There is a powerful synergy in having both diverse data and a wide range of processing options available from the same place, and as tools for managing security and governance continue to evolve side-by-side with YARN, we can expect an increasing move to multi-purpose, multi-tenant clusters.

Peter, another very very helpful post and helped me understand the important role of YARN
LikeLike